Get in touch
In den letzten Jahren hat das Thema künstliche Intelligenz immer häufiger Einzug in Unternehmen und deren IT-Projekte gehalten. Vor allem seit letztem Jahr ist insbesondere durch Unternehmen wie OpenAI und Angebote wie ChatGPT ein regelrechter Hype um die Möglichkeiten mit LLM (Large Language Models) und generativer KI entstanden. Viele Unternehmen fragen sich nun zu Recht, wie sie die neuen Möglichkeiten am besten einsetzen und dabei gleichzeitig auch Risiko-Themen wie beispielsweise Datenschutz berücksichtigen können. Denn diese Technologien bieten innovative Lösungen für zahlreiche geschäftliche Herausforderungen, von der Automatisierung komplexer Aufgaben bis hin zur Verbesserung der Interaktion mit Kunden.
In diesem Artikel geben wir einen Überblick über das transformative Potenzial der generativen KI sowie deren mögliche Einsatzbereiche. Darüber hinaus zeigen wir anhand eines Beispiels wie Sprachmodelle genutzt werden können, um aus unternehmenseigenen Informationen und Wissensdatenbanken neue Anwendungen und Mehrwerte zu erzeugen.
Generative künstliche Intelligenz (Generative KI) ist eine Form der künstlichen Intelligenz, die in der Lage ist, neue Inhalte wie z. B. Texte, Bilder, Videos oder Musik zu erzeugen, die sich qualitativ kaum (oder gar nicht mehr) von Inhalten unterscheiden lassen, die von Menschen erschaffen wurden.
Ein Teilbereich der generativen KI, der insbesondere in den letzten Jahren erstaunliche Fortschritte gemacht hat, sind die sogenannten "großen Sprachmodelle" (engl. Large Language Models oder LLMs), welche die Grundlage für bekannte Anwendungen, wie z. B. ChatGPT, Google Bard oder Midjourney, bilden. Ursprünglich für die Generierung von textbasierten Inhalten entwickelt, eignen sich Sprachmodelle inzwischen für eine Vielzahl von Aufgaben in den unterschiedlichsten Bereichen:
Technisch gesehen handelt es sich bei einem großen Sprachmodell um ein komplexes neuronales Netzwerk, das mit einer riesigen Menge von Daten trainiert wird (Bücher, Artikel, Webseiten u. ä.), um die Bedeutung, Konzepte und Zusammenhänge von natürlicher Sprache zu verstehen. Dieses trainierte Wissen wird in Form von sogenannten Parametern kodiert, die das Modell nutzt, um mit einer gewissen Wahrscheinlichkeit passende Antworten auf Benutzeranfragen zu generieren. Die "Größe" eines Sprachmodells bezieht sich auf die Parameteranzahl, also die Anzahl der Elemente im neuronalen Netz und damit auf die prinzipielle Fähigkeit komplexe Muster zu lernen. Beispielsweise verwendet die Architektur von OpenAIs GPT-4 etwa 1,76 Billionen Parameter. Je mehr Parameter ein Modell hat, desto mehr Rechenleistung wird benötigt. Neben der Parameteranzahl und den Trainingsdaten, gibt es zahlreiche weitere Merkmale anhand derer ein Modell bewertet werden kann. Auf einige gehen wir später noch detaillierter ein.
Anfragen an das Modell werden in Form eines "Prompts" gestellt. Dabei handelt es sich um den initialen Text, also z. B. eine Frage, den Beginn eines Satzes oder zusätzlichen Kontext, aus dem das Modell dann die Antwort generiert. Man muss allerdings beachten, dass Sprachmodelle auch falsche bzw. ungenaue Resultate liefern können, und spricht in diesem Fall von "Halluzinationen". Dies kann zum einen daran liegen, dass das Modell die Antwort auf eine Frage schlicht nicht kennt. So wurde ChatGPT 3.5 beispielsweise mit Daten trainiert, die nur bis Januar 2022 reichen, daher kann der Chatbot Fragen, die über diesen Zeitrahmen hinausgehen, nicht beantworten. Zum anderen basieren die Antworten eines Sprachmodells wie bereits erwähnt auf Wahrscheinlichkeiten (und natürlich der Qualität der zugrunde liegenden Trainingsdaten). Somit können auch faktisch falsche oder erfundene Inhalte erzeugt werden. Halluzinationen sind aber im Sinne von kreativen Antworten durchaus erwünscht, da das Modell auch neuartige Ideen produzieren soll, die sich nicht exakt so in den Trainingsdaten wiederfinden lassen.
Wichtige Kriterien für große Sprachmodelle sind unter anderem:
Der Unterschied zwischen Closed-Source- und Open-Source-Sprachmodellen liegt hauptsächlich in ihrer Zugänglichkeit und ihren Verwendungsmöglichkeiten. Closed-Source-Sprachmodelle werden in der Regel von großen Technologieunternehmen oder Forschungsinstitutionen entwickelt und meist kommerziell betrieben. Dies bedeutet, man muss für die Nutzung Lizenzgebühren, Abonnements oder die Kosten für API-Zugriffe bezahlen. Bei diesen Modellen ist der Quellcode nicht öffentlich zugänglich. Das bedeutet, dass Nutzer:innen und Entwickler:innen nicht einsehen können, wie das Modell strukturell aufgebaut ist, welche Algorithmen intern verwendet werden oder wie das Modell trainiert wurde. Demzufolge sind die Anpassungsmöglichkeiten der Modelle für eigene Applikationen oft beschränkt. Beispiele für bekannte Closed-Source-Sprachmodelle sind ChatGPT und GPT-4 von OpenAI, Google Bard oder Anthropics Claude.
Open-Source Modelle sind im Gegensatz dazu im Allgemeinen frei verfügbar und erlauben es Entwickler:innen, das Modell anzupassen oder zu erweitern, um dann darauf basierend auch eigene spezifische Lösungen umzusetzen. Sie sind meistens kostenlos und haben oft lizenzfreundliche Bedingungen, die eine breite Nutzung ermöglichen. Allerdings muss man beachten, dass der Betrieb eines Sprachmodells (je nach Größe des Modells, Anzahl an Zugriffen pro Tag) mitunter erhebliche Kosten für die IT-Infrastruktur verursachen kann, sei es nun eine On-Premise-Lösung oder die Verwendung von Cloud-Services. Bekannte Beispiele für (kommerziell nutzbare) Open-Source Modelle sind Metas LLama 2, Falcon von TII UAE, MosaicML MPT oder Mistral7B von Mistral AI.
Welches Modell nun das "beste" ist, lässt sich nicht allgemein beantworten, sondern hängt vom konkreten, umzusetzenden Anwendungsfall ab. Anhand von Faktoren wie Eignung/Performance/Anpassbarkeit des Modells, Betriebs-/Trainingskosten, gewünschter Datensicherheit etc. muss entschieden werden, ob man ein eigenes Modell betreiben möchte oder stattdessen auf eine kommerzielle Lösung zurückgreift.
Wie können nun aber existierende Sprachmodelle für eigene Anwendungen im Unternehmen angepasst werden? Dazu schauen wir uns im nächsten Abschnitt unterschiedliche Trainingsmöglichkeiten für LLMs an.
Wie können Sprachmodelle trainiert werden?
Retrieval Augmented Generation (RAG) beschreibt eine Architektur, die ein Information-Retrieval-Modell mit einem großen Sprachmodell kombiniert. Wenn eine Anfrage gestellt wird, sucht das Retrieval-Modell in seiner Datenbank nach potenziell relevanten Informationen. Diese Informationen können aus Textdokumenten, Webseiten oder anderen Datenquellen stammen und werden dann im Prompt zusammen mit der Anfrage an das Sprachmodell weitergegeben. Somit kann das Modell die zusätzlichen Informationen im Rahmen von In-Context-Learning nutzen, um die Anfrage besser zu verstehen und eine genauere Antwort zu generieren.
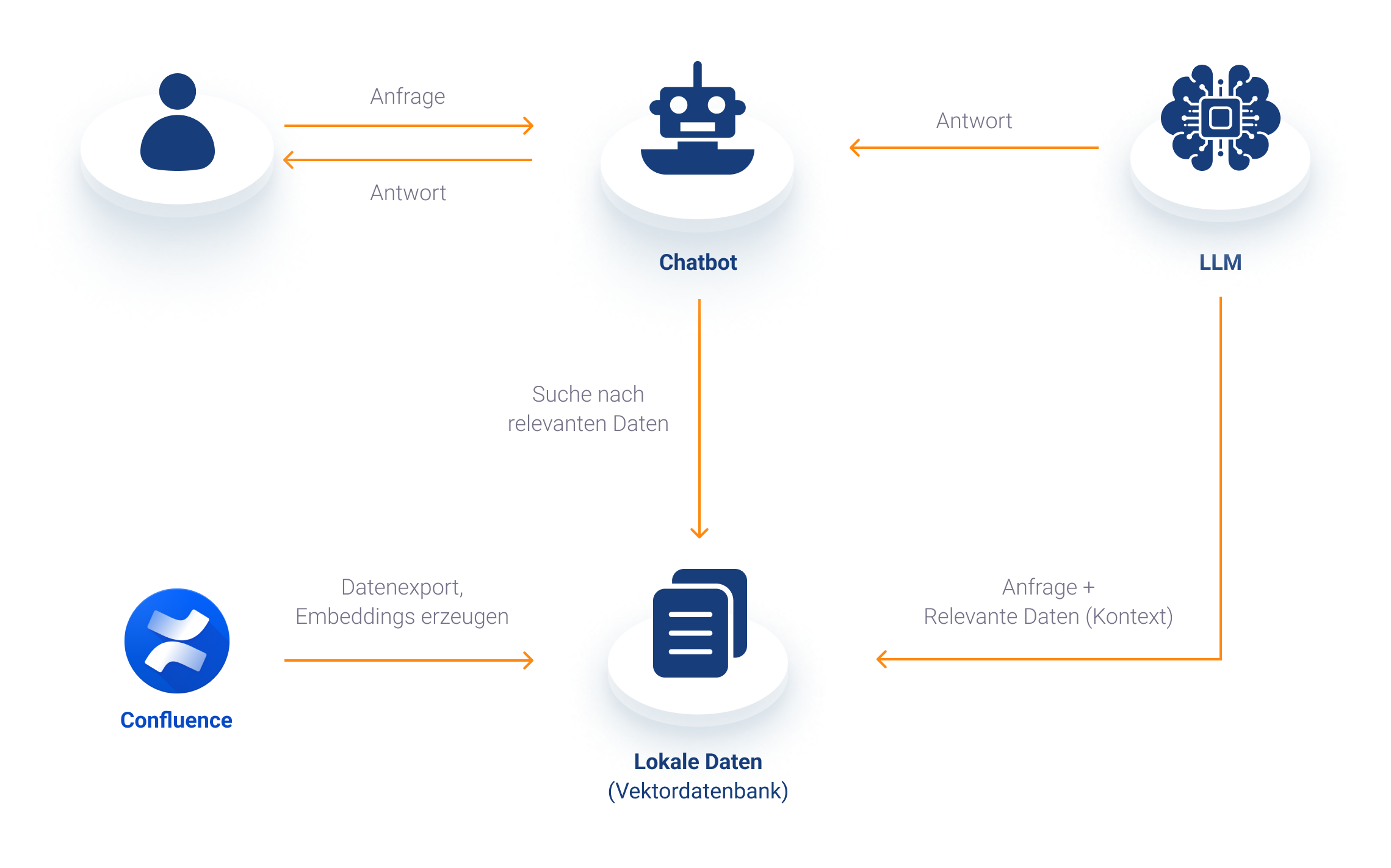
Betrachten wir als konkreten Anwendungsfall einen Chatbot, der eine Freitextsuche auf einer Wissensdatenbank wie z. B. Confluence ermöglicht. Wie genau findet das Retrieval-Modell in diesem Fall zu einer Abfrage die passenden Informationen?
Dafür sind einige Schritte im Vorfeld notwendig. Zunächst werden die zugrundliegenden Daten aus Confluence exportiert (zum Beispiel als HTML-Dokumente). Danach wird jedes dieser Dokumente in kleinere Teile wie Sätze oder Wörter zerlegt ("Chunks") und diese wiederum in eine Vektorrepräsentation ("Embeddings") umgewandelt, die für die Verarbeitung durch maschinelle Algorithmen besser geeignet ist. Diese Vektoren sind so gestaltet, dass sie die Bedeutung und die Beziehungen zwischen verschiedenen Wörtern oder Phrasen abbilden, so dass Wörter mit ähnlichen Bedeutungen im Vektorraum (idealerweise) nahe beieinander liegen. Die generierten Vektoren und eine Referenz auf die zugehörigen Dokumente werden zum Abschluss in einer Vektordatenbank wie z. B. ChromaDB oder Pinecone für den schnellen Zugriff gespeichert. Wird nun eine Frage über den Chatbot gestellt, wird diese, wie die Dokumente vorher, in ihre einzelnen Bestandteile zerlegt, in Vektoren umgewandelt und mit den Einträgen in der Vektordatenbank verglichen. Die Inhalte, die der Frage am "ähnlichsten" und somit am relevantesten sind, werden von der Datenbank zurückgeliefert und dem Sprachmodell als Kontext mitgegeben. Die vom Sprachmodell generierte Antwort wird dann als Ergebnis im Chatbot angezeigt.
Die Integration von großen Sprachmodellen in Unternehmensanwendungen markiert einen Wendepunkt in der digitalen Transformation. Diese Modelle bieten Unternehmen nicht nur die Möglichkeit, ihre Prozesse zu optimieren und die Kommunikation zu verbessern, sondern sie eröffnen auch neue Horizonte für personalisierte Services, präzise Analysen und effiziente Entscheidungsfindung. Ihre Vielseitigkeit macht sie zu einem nützlichen Werkzeug für Unternehmen, die nach innovativen Lösungen streben, um in einer sich ständig verändernden und zunehmend datengetriebenen Geschäftswelt erfolgreich zu sein und zu bleiben.




